
Descripción
Este curso de ingeniería de datos con Microsoft Fabric está dirigido a profesionales que diseñan e implementan soluciones de datos. Con módulos prácticos y laboratorios oficiales, aprenderás a ingestar datos, transformar con PySpark y KQL, diseñar arquitecturas Lakehouse y Data Warehouse, y crear flujos en tiempo real. Dominarás además la gobernanza del dato, la monitorización, la optimización y la integración continua en entornos productivos. Ideal para preparar el examen DP‑700 (Fabric Data Engineer Associate), con un enfoque técnico, casos reales y guía paso a paso para su implantación en entornos empresariales.
Objetivos del curso
Qué aprenderá
A quién va dirigido
Nivel de experiencia
Objetivos del curso
Este curso busca capacitar de forma técnica y práctica:
-
Diseñar e implementar soluciones de ingesta y transformación de datos con Fabric.
-
Desarrollar arquitecturas Lakehouse y Data Warehouse eficientes.
-
Orquestar flujos batch y tiempo real con Spark, KQL, Eventstream/Eventhouse.
-
Configurar entornos seguros y gobernados con roles, lineage, monitorización.
-
Implementar CI/CD y optimización de coste, rendimiento y latencia.
Qué aprenderá
-
Ingesta y transformación de datos (batch/realtime)
-
Construcción de Data Lakes & Lakehouse
-
Desarrollo con PySpark, T-SQL y Kusto Query
-
Gobernanza: lineage, sensibilidad, roles
-
Monitorización y optimización continua
-
CI/CD en plataformas Microsoft Fabric
A quién va dirigido
Profesionales con experiencia en ingeniería de datos (SQL, PySpark, KQL) que quieran diseñar soluciones completas en Microsoft Fabric para análisis y alta disponibilidad.
Nivel de experiencia
Profesional intermedio-avanzado: experiencia previa en ingesta y transformación de datos, flujo de datos con Spark o KQL.
Temario completo – Ingeniero de datos con Microsoft Fabric (DP‑700)
Módulo 1 – Ingesta de datos con Fabric
-
Principios de ingesta batch e incremental
-
Orquestación usando Data Pipelines (Spark, KQL, Eventstream)
-
Prácticas: ingestión multimodal y control de calidad
Módulo 2 – Arquitectura Lakehouse en Fabric
-
Diseño de Lakehouse: OneLake, Shortcuts
-
Diferencias entre Data Lake y Warehouse
-
Ejercicios con PySpark y T-SQL
Módulo 3 – Inteligencia en tiempo real
-
Configuración de Eventstream y Eventhouse
-
Procesado streaming con KQL DB
-
Laboratorio: análisis en tiempo real con dashboards
Módulo 4 – Implementación de Data Warehouse
-
Modelado T-SQL, procedimientos, funciones
-
Orquestación de datos y control transaccional
-
Optimización del rendimiento y escalado
Módulo 5 – Administración del entorno Fabric
-
Seguridad: roles, sensibilidad, control de acceso
-
Gobierno: lineage, etiquetas, endorsement
-
Monitorización: Monitor Hub, Spark UI
Módulo 6 – CI/CD y DevOps para Fabric
-
Despliegues con Azure DevOps y Pipelines
-
Control de versiones y gestión de releases
-
Estrategias de rollback y validación
Módulo 7 – Optimización y costes
-
Análisis de costes de computación y almacenamiento
-
Configuraciones para alta disponibilidad
-
Buenas prácticas en escalabilidad y coste/beneficio
Módulo 8 – Preparación para el examen DP‑700
-
Revisión de objetivos del examen
-
Simulacros y preguntas tipo test
-
Recomendaciones para fecha óptima de examen
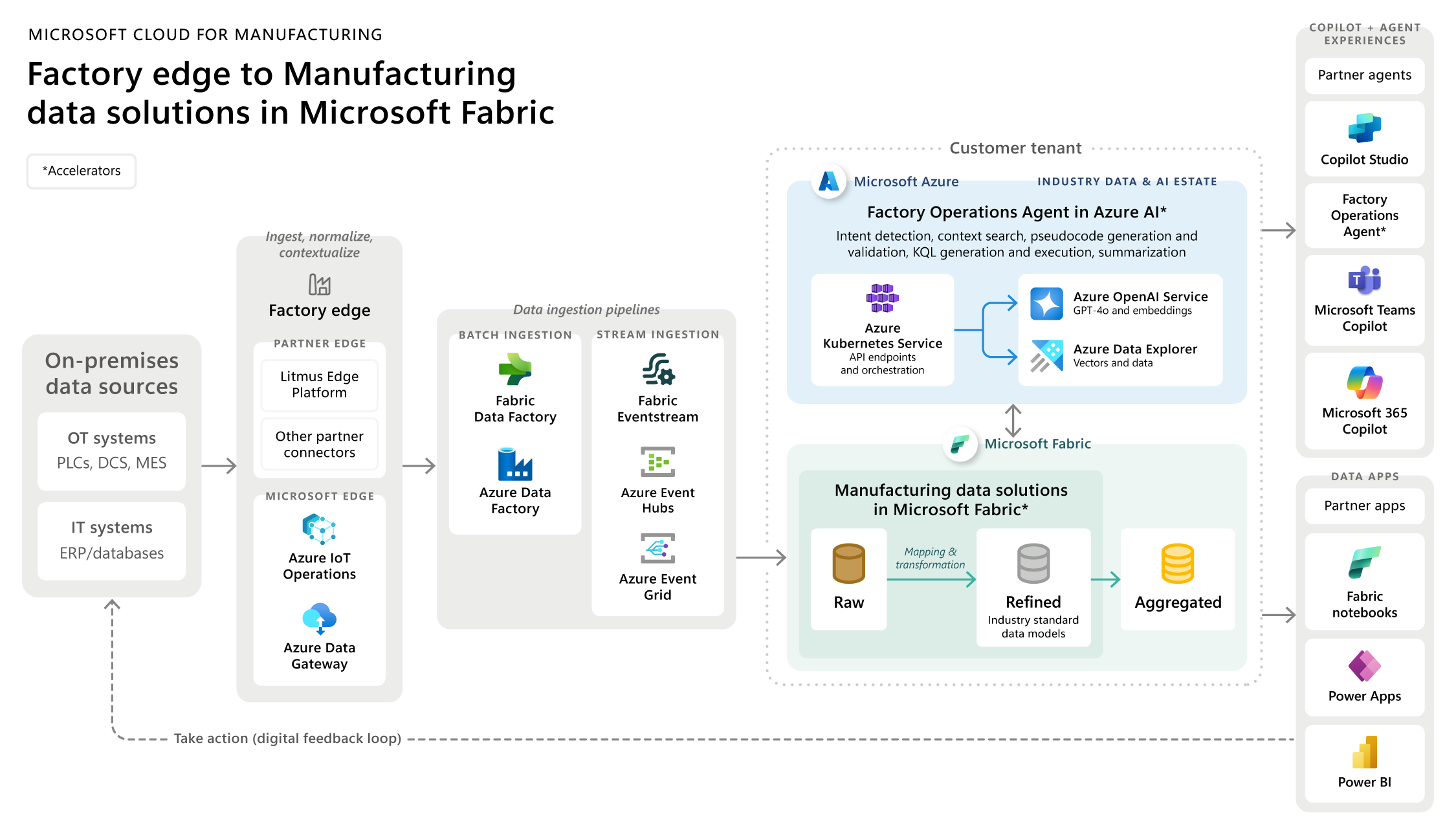
Información sobre el examen:
-
El examen DP‑700 certifica las competencias como Ingeniero de datos en Microsoft Fabric. Evalúa tres bloques principales:
-
Implementación y administración de entornos de análisis (30–35 %)
-
Ingesta y transformación de datos (30–35 %)
-
Supervisión y optimización de soluciones analíticas (30–35 %)
Tecnologías clave: PySpark, SQL, KQL, Spark Notebooks, OneLake y Microsoft Fabric.
Superarlo otorga la certificación:Microsoft Certified: Fabric Data Engineer Associate.
-
Inscríbete al curso gratuito SEPE
Cursos para trabajadores del sector servicios y personas desempleadas. Plazas limitadas. Próximas ediciones de junio a septiembre 2026.



